CQRS and Event Sourcing @php[architect]
Volume 20 - Numéro 2 (02/2021) by Junior Grossi - USA / Traduit par Jon, relecture et correction par Pierre Crespel
La mise en œuvre du CQRS et de l'Event Sourcing dans votre application peut vous permettre d'améliorer les performances et le temps de réponse à une requête utilisateur et de résoudre plus facilement des bugs. Bien qu'ils ne soient pas nouveaux, ils sont utiles quand vous avez besoin de séparer les responsabilités ou tracer l'évolution de vos données, donc pas seulement sur votre code. Cet article devrait vous permettre d'avoir une meilleure compréhension de leurs fonctionnements et de leurs utilités dans votre application.
Le CQRS et l'Event Sourcing n'est pas un seul modèle de conception d'architecture logiciel mais chacun de ces patterns peut être mis en oeuvre indépendamment ou ensemble. Ils permettent de résoudre différents problèmes, mais ensemble ils se complètent et sont complémentaires des autres modèles de conception. La bonne nouvelle est que vous n'avez pas à changer votre architecture actuelle. Vous pouvez les appliquer à un ou plusieurs user case, non à l'entièreté de votre application. Vous pouvez appliquer le CQRS et l'Event Sourcing sur du code legacy, que vous utilisez surement au boulot, sans restriction.
CQRS
CQRS est l'acronyme de Command Query Responsibility Segregation, qui a pour but de séparer la responsabilité des opérations de lecture et d'écriture. Lors d'une opération d'écriture, nous utilisons le pattern Command/Commande, qui modifie les données. Lors d'une lecture, nous utilisons le pattern Query/Requête. La question est maintenant : pourquoi? Les raisons principales sont l'extensibilité et la performance. Quand on sépare ces deux opérations en différents "flux", il est plus facile d'identifier quand et où nous avons besoin de plus de ressources. En même temps, ces deux nouveaux "flux" sont simplifiés, ce qui a un impact direct sur les performances. Nous ne séparons pas habituellement ces deux opérations quand nous développons une application Web, et sans problème en général. Comme énoncé dans l'introduction, le CQRS est à implémenter uniquement dans des cas spécifiques où il est avantageux de l'utiliser et quand nous avons des difficultés pour corriger des bugs.
Tous les exemples de code sont écrits en PHP 8.
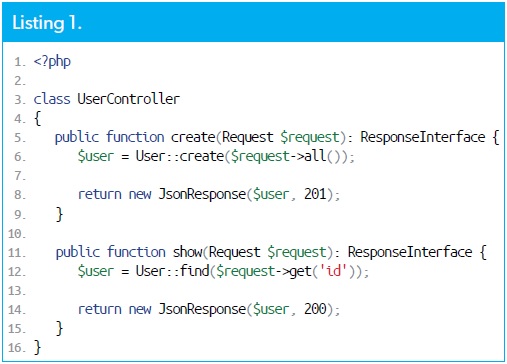
Considérons une classe courante UserController décrite dans "Listing 1". Cela vous est peut-être familier.
Stockage
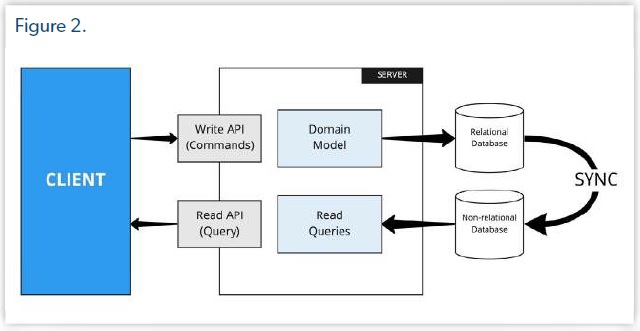
L'un des avantages significatif de la séparation des opérations de lecture et d'écriture en deux flux distincts est de pouvoir choisir le stockage approprié pour chacun.
Nous savons que par exemple certains moteurs de stockage sont plus rapide que les bases de données relationnelles. Redis est plus rapide que MySQL pour lire des données, mais MySQL peut être mieux pour écrire les données par rapport à votre domaine de données. Pourquoi ne pas choisir les deux?
Pourquoi nous ne pourrions pas utiliser Redis pour les opérations de lecture et une base de données relationnelle comme MySQL ou autre pour les opérations d'écriture. C'est le but! Avec un peu de travail supplémentaire, vous pouvez le faire.
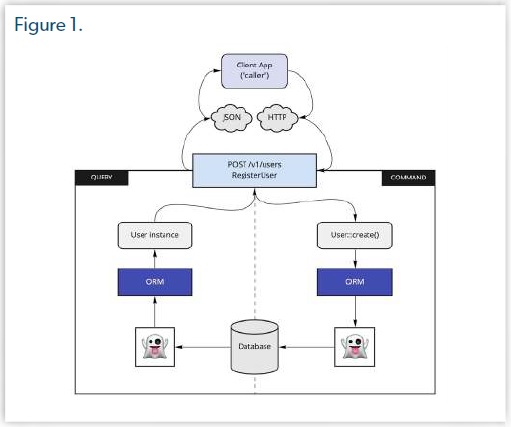
Lorsqu'une application cliente consomme l'API de création d'un utilisateur, nous devrions utiliser MySQL pour cette opération et laisser Redis se mettre à jour avec les nouvelles données ajoutées (Figure 2).
Donc à chaque opération d'écriture, nous devons notifier le changement à la base de données dédiée à la lecture. Cette approche a un coût mais les avantages en valent la peine.
Commande
Voyons maintenant un peu plus en détail comment fonctionne la séparation des opérations d'écriture et de lecture. Nous pouvons utiliser le pattern Commande pour les opérations d'écriture et le pattern Query pour la lecture. Nous représentons généralement le pattern Commande comme un "Command Handler/Gestionnaire de commandes" ou même des "Use Case/Cas d'Utilisation". L'idée est d'avoir deux classes : la classe Command et la classe Handler. La classe Command a pour seule responsabilité le transport des données, qui seront traitées par la classe Handler. Le Handler contient la logique à exécuter, mais en entrée nous avons une instance de la classe Command. Lisons du code pour comprendre concrètement ce pattern d'architecture. Représentons le flux "inscription d'un utilisateur" en utilisant le pattern Command Handler. Commençons par la classe contrôleur qui recevra notre instance Handler en tant que dépendance.
Le contrôleur
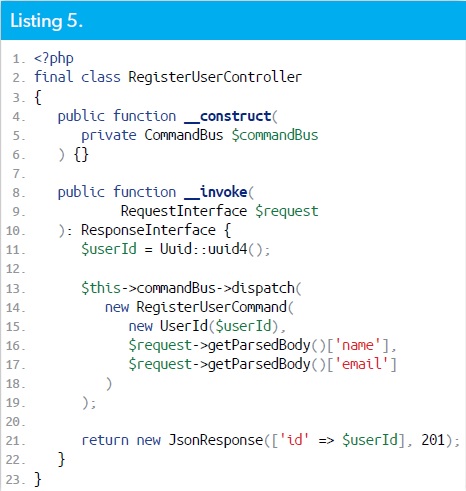
Le "Listing 2" montre la classe RegisterUserController :

La commande
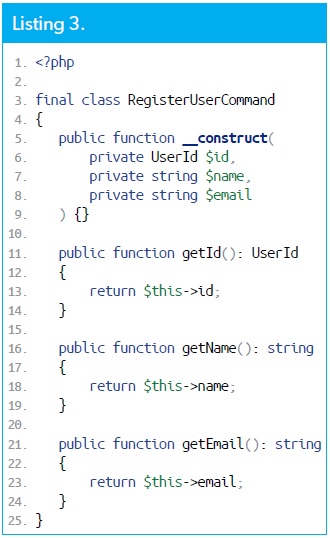
Nous envoyons les données du handler via la création une nouvelle instance de la classe RegisterUserCommand (Listing 3). Il est courant d'omettre le suffixe "Command", mais pour plus de clarté dans les explications, il est laissé.
Le gestionnaire
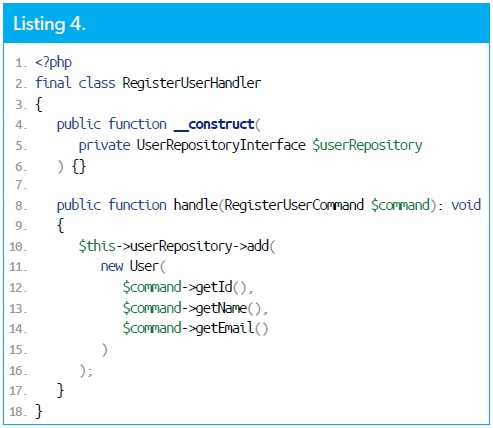
C'est dans le gestionnaire que la logique est définie. Habituellement, la classe Handler a juste une seule méthode publique appelée handle() ou execute(). Cette méthode publique reçoit une instance de la commande comme paramètre, comme illustré dans le Listing 4.
Ajout d'un bus de commande
OK, vous voulez enregistrer un utilisateur. Je sais quoi faire et comment le faire. Voici l'ID qui sera utilisé lors de l'enregistrement. Le traitement est en cours.
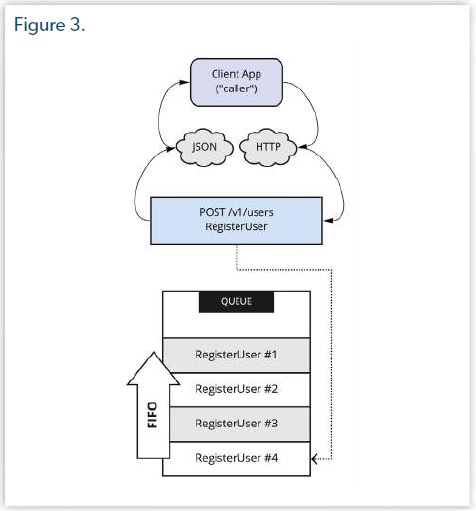
L'idée ici est que l'utilisateur n'est pas encore créé, mais nous allons envoyer un "job" dans la file d'attente qui sera traité en temps voulu, probablement une ou deux secondes plus tard, mais pas immédiatement. Cette technique permet de ne pas retarder l'envoi de la réponse puisqu'elle n'attend pas le traitement par la base de données de la demande de création d'un utilisateur. Notez que nous n'avons plus la dépendance RegisterUserHandler, mais CommandBus. Cette instance reçoit la commande qui doit d'exécuter en tâche de fond. Fait intéressant, nous n'avons aucune référence à la classe Handler, mais la commandBus est suffisamment intelligente pour savoir que le Handler responsable de RegisterUserCommand est le RegisterUserHandler. Puis en arrière-plan (au niveau de la file d'attente), lorsque nous recevons la commande à exécuter, nous créons une nouvelle instance du gestionnaire puis nous passons la commande à la méthode handle(). C'est bien, mais en cas d'erreur? Et si le traitement ne fonctionne pas? Dans ce cas, nous l'ajoutons à nouveau dans la file d'attente. Même si la base de données est complément hors service, le job sera traité plus tard. Une approche valable est d'accroître la priorité de ce job en particulier, pour être sûr de l'exécuter avant les autres jobs de la file d'attente (Figure 3).
Requête
Nous avons vu que la Commande est responsable de changer les données. Maintenant il est temps de comprendre comment utiliser la Query pour les lire. Supposons que nous ayons un cas d'utilisation "trouver un utilisateur" comme dans le listing 6 :

Quand utiliser CQRS ?
Séparer la responsabilité de la lecture et de l'écriture ne doit pas être appliqué à l'ensemble d'une application, mais pour certains cas d'utilisation spécifique où vous avez besoin de meilleures performances et où le résultat de la commande n'est pas nécessaire pour répondre à la demande initiale. Par exemple, si vous travaillez avec une architecture microservice, généralement la communication asynchrone est en principe utilisée pour envoyer des messages entre les services. Vous pouvez mettre en oeuvre facilement le CQRS si vous n'avez pas à changer radicalement votre architecture actuelle pour ajouter une file d'attente et une communication asynchrone. Le CQRS peut être appliqué aux points d'accès API lents. Certaines actions prennent plus de temps si elles ont besoin de vérifier dans différentes sources de données ou si des évènements sont en attente de réponse d'autres services. Et donc en ajoutant le CQRS, vous pouvez faire évoluer vos actions en retournant rapidement une réponse, et répartir le travail entre plusieurs workers en tâche de fond sans affecter les performances. Vous allez avoir besoin de vérifier l'état d'un processus pour savoir s'il a été traité ou non. Dans ce cas, l'utilisation des WebSockets est excelllente et sa mise oeuvre est rapide pour établir une connexion directe entre le client et le serveur. Après vous pouvez notifier au client quand "l'action" est faite.
Event Sourcing
La manière la plus simple pour comprendre l'Event Sourcing est de prendre en compte chaque étape requise d'une action comme différents évènements. Chaque fois que vous avez un changement d'état, vous déclenchez un nouvel évènement qui est enregistré.
L'idée derrière ce concept est de tracer chaque changement d'état de votre cas d'utilisation. Ainsi vous avez la possibilité d'identifier les changements de données et même "faire un voyage dans le temps" dans les données, en atteignant un état spécifique à un moment donné.
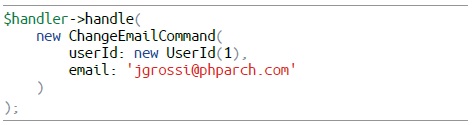
Voyons un nouveau cas d'utilisation : "modifier l'adresse email d'un utilisateur". Pour cela, nous aurons une classe logique nommée ChangeEmailHandler et une classe responsable des données nommée ChangeEmailCommand.
Tout d'abord voici l'état actuel de notre base de données :
 Ensuite, nous voulons modifier l'adresse e-mail de l'utilisateur, nous appelons donc notre gestionnaire de commandes :
Ensuite, nous voulons modifier l'adresse e-mail de l'utilisateur, nous appelons donc notre gestionnaire de commandes :
 Après avoir exécuté ce code, quel est le résultat attendu? Nous finirions probablement par avoir en base de données ceci :
Après avoir exécuté ce code, quel est le résultat attendu? Nous finirions probablement par avoir en base de données ceci :
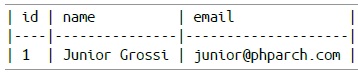 Quel problème avons nous ici? Qu'est-ce qui a changé? Pourquoi ces données ont-elles été modifiées? Malheureusement, nous n'avons pas de réponse à cette question sauf si vous vérifions les logs pour ce scénario, couvrant pas à pas ce qu'il s'est passé pendant le processus.
Alors, voici l'Event Sourcing :
Dans le cas où l'Event Sourcing est utilisé, nous enregistrons toujours les changements d'état, montrant le «quand» et le «quoi». Voir le listing 7 :
Quel problème avons nous ici? Qu'est-ce qui a changé? Pourquoi ces données ont-elles été modifiées? Malheureusement, nous n'avons pas de réponse à cette question sauf si vous vérifions les logs pour ce scénario, couvrant pas à pas ce qu'il s'est passé pendant le processus.
Alors, voici l'Event Sourcing :
Dans le cas où l'Event Sourcing est utilisé, nous enregistrons toujours les changements d'état, montrant le «quand» et le «quoi». Voir le listing 7 :

Les évènements
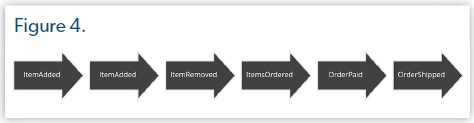
Chaque événement est responsable d'un changement d'état qui doit être enregistré. Tous les évènements sont notifiés au passé car cela représente quelque chose qui s'est déjà produit, comme "l'email de l'utilisateur a été modifié", "l'utilisateur a été créé", "la commande a été payée", "le produit a été ajouté", etc... Une suite d'évènements enregistrée permet de savoir pas à pas les changements que l'utilisateur a effectué pour terminer une action. Sur une plateforme e-commerce par exemple, nous pourrions suivre et enregistrer tous les évènements relatifs au panier d'un utilisateur, comme sur la Figure 4.
Implémentation
L'Event Sourcing est un modèle de conception que vous ajoutez à certains cas d'utilisation pour vous aider sur des problèmes spécifiques. Ces cas d'utilisation font partie de votre domaine, donc l'implémentation de ce pattern devra également faire partie de votre domaine. Il y a des frameworks et librairies connus pour vous aider dans sa mise en oeuvre. Habituellement, ce sont des composants d'autres frameworks ou même d'autres librairies. En utilisant ces librairies, vous ajoutez du métier externe à votre domaine dans votre domaine, ce qui n’est pas souhaitable sur le long terme. Si vous voulez utiliser l'Event Sourcing, utilisez-le comme vous le voulez, sans un framework, pour vous assurer que son implémentation se limite à vos besoins. Tout autre changement de la librairie tiers n'impactera pas le domaine de votre application. Dans le même temps, il est difficile d'implémenter quelque chose dont nous n'avons aucune idée du fonctionnement. L'auteur, Junior Grossi, recommande d'utiliser le code à la base du projet prooph comme référence pour comprendre son fonctionnement, comment les évènements sont tracés et enregistrés. Jetez un oeil sur deux dépôts en particulier :
- http://github.com/prooph/common
- http://github.com/prooph/event-sourcing, déprécié mais reste néanmois une mine d'informations.
Agrégats
Dans ces dépôts, vous trouverez un des concepts qui est omniprésent dans l'Event Sourcing, les "agrégats". Ils sont utilisés pour représenter les changements d'état, ou simplement "ce qui s'est passé." Les agrégats démontrent la "cohérence" d'un état et sont responsables d'assurer le passage d'un état à un autre. Ils sont dépositaires d'un ensemble de règles métier à valider pour passer à l'étape suivante. Dans ce cas, quand nous disons "règles métier", nous avons une infinité de règles que nous pourrions appliquer, mais elles doivent être appliquées dans des cas spécifiques, par exemple :
- Un panier commence toujours vide. Si vous avez déjà un article dans le panier, il est déjà en cours, et ne peut pas être réinitialisé.
- Un article ne peut être ajouté que s'il est disponible. Si nous n'avons pas cet article en stock ou si la vente de cet article est suspendue, il ne peut pas être ajouté au panier.
- Le nombre d'articles du même type de produit ne peut pas être supérieur au stock disponible. Si il y en a deux en stock et que vous en vouliez trois, vous ne devriez pas pouvoir en commander plus de deux.

Conclusion
Faisons un petit récapitulatif de ce que nous avons appris :
- Le CQRS rompt les responsabilités entre les opérations en lecture et en écriture. Vous pouvez utiliser un gestionnaire de commandes pour représenter les cas d'utilisation, puis utiliser un bus de messages pour envoyer les commandes à la file d'attente pour améliorer les performances et réduire le temps de réponse. Chaque nouvel élément ajouté aux données de la base de données relationnelle nécessite une synchronisation de la base de données de lecture en utilisant une file de traitement.
- L'Event Sourcing enregistre chaque changement d'état à l'aide d'événements. Tous les noms d'événements doivent être écrits au passé. Lorsque vous combinez évènements et agrégats, vous savez que l'ensemble des règles de gestion ont été satisfaites. Toujours enregistrer un nouvel évènement avec des informations utiles, comme le "quand" et le "quoi". Conservez l'historique de toutes les changements pour pouvoir suivre les cas d'utilisation.